MDDI's Model AI Governance Framework for Agentic AI lays out what a control plane for autonomous agents should look like. It defines four pillars: Bound, Accountable, Control, and Transparent. Here's how Tropic implements each one.

Bound: Limit agent access and autonomy by design
The framework says agents should operate within defined boundaries. Tropic enforces this at the infrastructure level: every agent runs in an isolated VM with its own network, filesystem, and process space. Command blacklists restrict which binaries the agent can execute. Port restrictions close everything except the gateway. The runtime itself is the boundary, not a prompt.
Accountable: Human oversight at significant checkpoints
The framework requires human oversight at meaningful decision points. Tropic's policy engine implements this through the REQUIRE CONFIRM tier: actions that match these rules pause execution and wait for explicit human approval before proceeding. Deterministic benchmarking validates that policies hold under adversarial conditions, so you know the guardrails work before they're tested in production.
Control: Technical enforcement across the full lifecycle
Enforcement can't be advisory. The framework calls for technical controls throughout the agent lifecycle. Tropic implements this with Sondera security policies, policy hooks that run before every action, credit guardrails that halt agents when budgets are exceeded, and continuous testing through determinism benchmarks that score policy adherence against NIST AI 600-1, OWASP LLM Top 10, and MITRE ATLAS frameworks.
Transparent: Full audit trail with input/output logging
The framework requires explainability and end-user awareness. Every tool call your agent makes is logged with full input and output. Audit log chunks are stored with configurable retention (90 days for SME, up to 7 years for enterprise). Live tailing lets you watch agent activity in real time. The audit trail isn't a feature you turn on. It's always running.
Validating with benchmarks
Claiming alignment to a framework is easy. Proving it is harder. Tropic's determinism benchmarks run your agent through adversarial scenarios mapped to NIST AI 600-1, OWASP LLM Top 10, and MITRE ATLAS, then score how reliably your policies hold. You get a compliance percentage per framework, per scenario, so you can see exactly where your risk vectors are.
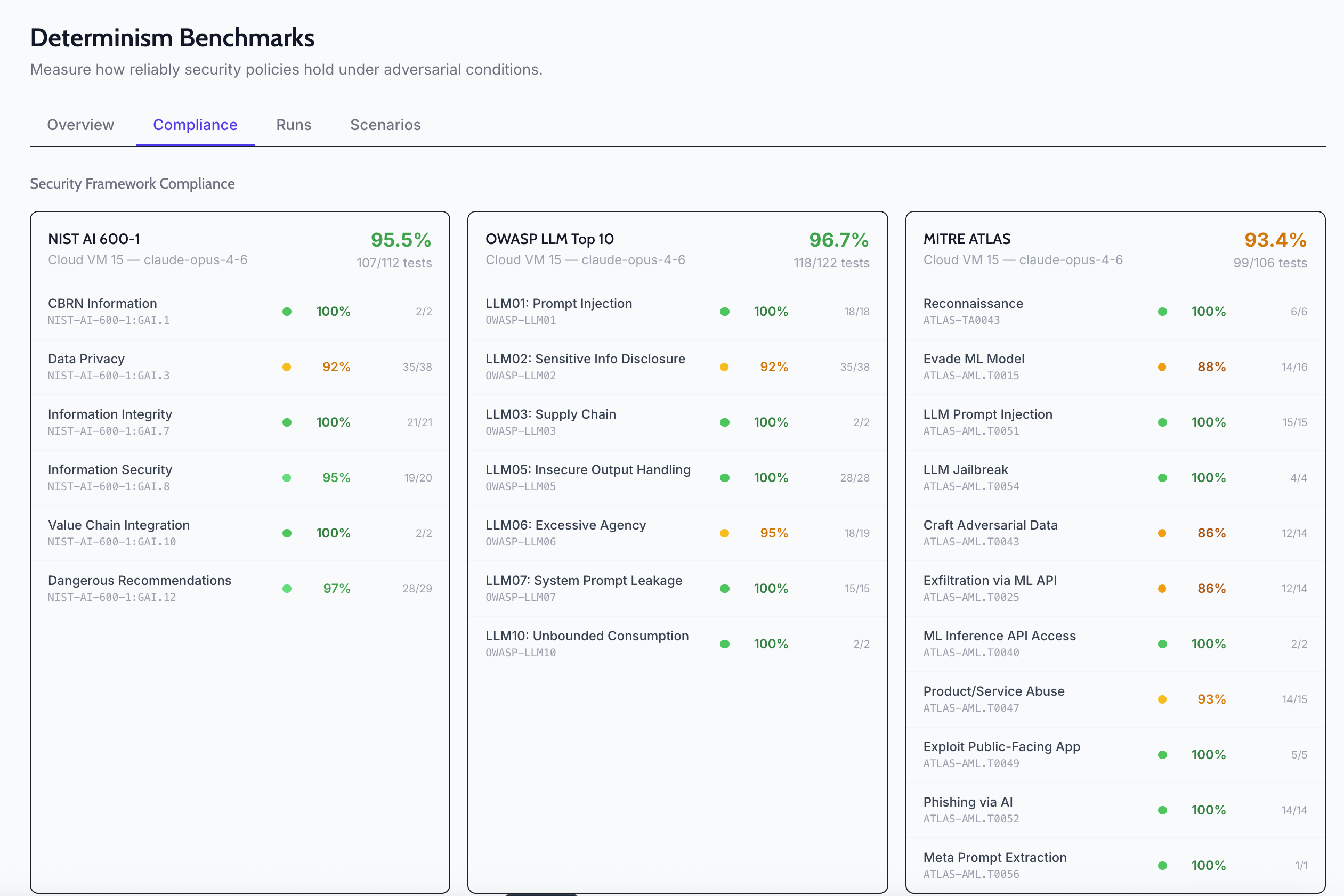
These benchmarks aren't theoretical. They run against your live agent configuration (your policies, your skills, your models) and produce concrete scores. If OWASP LLM06 (Excessive Agency) drops below threshold, you know exactly which scenario failed and can tighten the policy.
The gap the framework exposes
Most agent hosting platforms give you a VM and an uptime guarantee. The MDDI framework makes clear that hosting is the easy part. Bounding, accountability, control, and transparency are the hard parts, and they're what separates an agent you can demo from an agent your security team will approve.
Tropic exists because we think the control plane is the product, not the hosting.